Kafka作为使用最广泛的流消息系统,被广泛应用企业流数据处理和互联网实时处理平台,可以在该平台传输各种类型的数据。但是Kafka对其处理的消息大小是有限制的。在最近的版本中,其最大消息大小被限制在2GB以下。官方建议最好是把单个消息的大小限制在10k左右,Kafka的设计本来就是为了处理巨量的消息,而不是用来传输大型的消息的。 我们可以通过以下的配置修改消息的大小,但是强烈不建议这样做。在Kafka系统上传输大型的消息会对整个系统的性能造成很大的负面影响,很有可能把整个系统搞崩溃。
- broker
- message.max.bytes :500000000B(500M),单个消息的最大值 。
- replica.fetch.max.bytes :512000000B(512M),单个消息的最大值broker可复制的消息的最大字节数,比message.max.bytes大。这个512M肯定已经会对性能产生非常不好的影响了。
- consumer
- fetch.message.max.bytes:500000000B(500M) 消费者能读取的最大消息,大于或等于message.max.bytes
- producer
- max.request.size:500000000B(500M) 生产者能请求的最大消息,大于或等于message.max.bytes
那如果我们确实会有一些比较大的消息,比如视频信息,大的二进制文件需要传送怎么办呢?我们通常采用以下两种方式来处理。 方法1:分块,这个也是LinkedIn团队推荐的的方式: 这个方法就是把大型的数据块拆成多个小的消息,然后需要给每一个消息设置编号,并把同一个数据块的消息设置ID,我们可以用下面的方式发送大数据块。 上面的例子里,我们把一个数据拆成了3个消息发送,type指的是消息类型,如果是chuck,则指的是需要进行合并的消息数据。uuid是这个数据块的标识。chunk_pos是表示某条消息在原来的数据块拆分序号,chunk_max表示拆分的消息总数。一旦三个分片消息都接受完成,这三个消息就会被合并成原来的数据块。 每一个消息我们都会有uuid,chunk_pos和chunk_max这几个元数据。消息格式如下:
 发送消息:
发送消息: 接收消息:必须保证接受到了所有的消息才能够合并后发送给用户。要做到这一点其实要保证所有的消息不能够在接受的时候丢失。 #### 方法二:外部存储
接收消息:必须保证接受到了所有的消息才能够合并后发送给用户。要做到这一点其实要保证所有的消息不能够在接受的时候丢失。 #### 方法二:外部存储
除了直接通过Kafka发送拆分的消息外,我们还可以采用另外一种方式,把数据直接存储在另外一个外部数据存储系统中。在消息中只发送存储的Key或者ID 消息的格式如下:  消息的发送需要处理两个操作,第一个是把数据存入外部存储系统中,另外一个操作就是把带有存储的key/id的消息发送到Kafka的队列里去。
消息的发送需要处理两个操作,第一个是把数据存入外部存储系统中,另外一个操作就是把带有存储的key/id的消息发送到Kafka的队列里去。 操作外部存储的部分,则需要有以下功能:写入,读取和回滚; 下面的代码是示例封装一个消息:
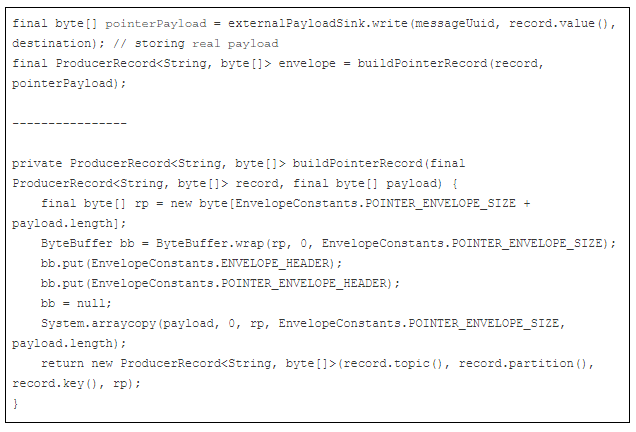 下面的代码示例是接收到消息并从外部存储读取数据: - 检查是否是特殊的消息,需要读取外部存储中的数据
下面的代码示例是接收到消息并从外部存储读取数据: - 检查是否是特殊的消息,需要读取外部存储中的数据
- 从消息里取得存储的key/ID
- 通过key读取外部存储的数据
- 返回结果给用户



文章评论
Awesome post! Keep up the great work! :)